"Undisclosed"
Reframing an industrial app design challenge — from knowledge tool to AI-powered behavioral engine.

-
Client:
"Undisclosed"
-
Year:
2025
-
Type:
Design Challenge
-
Status:
Presented
-
Role:
Senior Product Designer
A design challenge brief arrived as part of a hiring process — evenings borrowed from an active engagement. I treated it as the closest thing to a real discovery context I was going to get.
The company operated in predictive maintenance, with AI at the core of how it approached the problem. In environments where a stopped machine translates directly into financial loss — compounding by the minute — preventing failure before it happens isn't a feature. It's the business.
The scenario was concrete: a technician mid-repair, documentation inaccessible, a more experienced colleague who might have known the answer unavailable, the production line waiting. Two problems inside one moment — the knowledge locked in manuals, and the knowledge locked in people. The ask: a platform that would unlock both — fast access to technical documentation organized by equipment type and failure category, and a way for experienced technicians to contribute what they know so others could find it when it mattered.
Read that way, the shape of the solution is obvious: a searchable knowledge base organized around the equipment types and failure categories the brief defines, a contribution layer for technicians to document solutions — text, photos, video — and a mechanism to surface what works. It's a reasonable answer. It's also the answer the brief invites.
What follows is deliberately rich — more than a v1 product engagement would ship. That's the point. A real engagement answers what ships first? A design challenge answers how does this candidate think? It's the one format that makes process as visible as output: how a candidate thinks about ambiguity, how far they look beneath a brief, how their architectural judgment holds up against business context. The richness here isn't ambition for its own sake — it's the answer to the only question that determines fit, on both sides.
Diagnosis
Something in the brief didn't hold.
The scenario describes a technician who, unable to find the answer in documentation, tries to call a more experienced colleague. If that call goes through and the colleague explains the fix — problem solved. Machine up, line running.
But the knowledge stays between two people. And a phone call leaves no trace even the two of them can return to — no transcript, no structure, no searchable record. Two layers of context lost at once: the social layer, because the knowledge never reaches anyone else; and the medium layer, because speech itself leaves nothing a platform — or an AI — can learn from.
That detail is easy to miss, and easy to dismiss. The brief doesn't ask you to notice it. But it contains a structural problem the stated solution doesn't address: if the platform's fallback is a phone call, every problem solved that way is a problem that never reaches the shared record. The contribution the platform was designed to enable doesn't happen.
That was the thread worth pulling — the diagnosis most people skip, and the one everything else depends on.

The company's own answer
The response wasn't in the brief. It was in the company. Before anything was designed, I studied how their existing products worked — what they solved, what made them thrive. Their flagship predicted machine failures before they happened. To understand why it was thriving — not just what it did — I mapped it through an adaptation of the Kano Model, reoriented from feature prioritization to business vision.
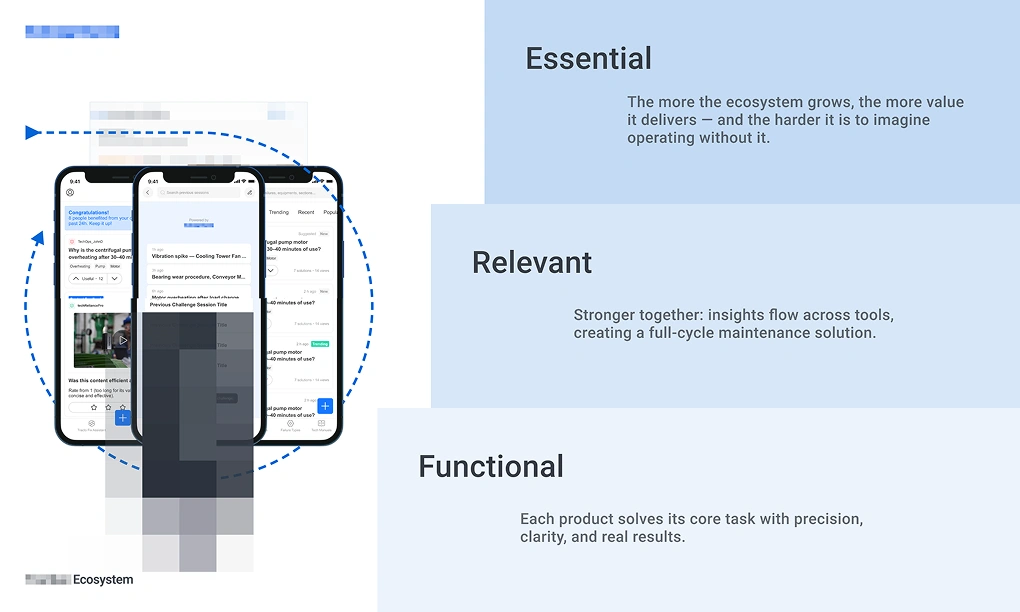
Where Kano's Basic tier asks "does this feature work?", Functional asks "does this product solve the problem?" Where Performance asks "does it solve it better than alternatives?", Relevant asks "has it earned preference?" And where Excitement asks "does this feature delight?", Essential asks something structurally different: "has this product become so embedded in how people work that removing it would leave a gap?" Three tiers, each representing a different relationship between the product and the people who depend on it. Kano's other two tiers — Indifferent and Reverse — aren't part of this reframe. A vision map is aspirational; it has no use for what users don't care about or actively reject.
Applied to the flagship:
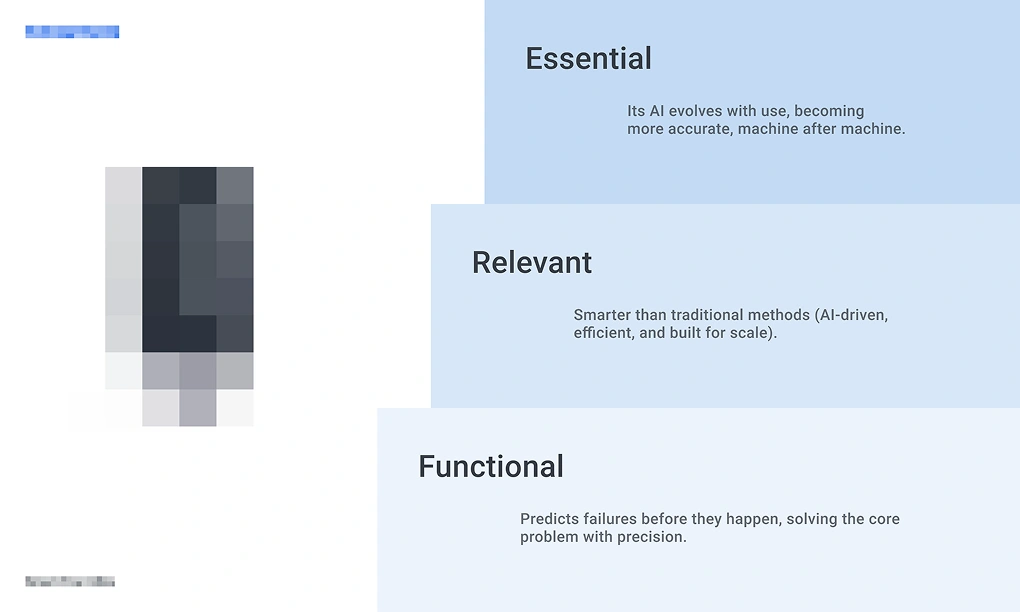
Functional: Predicts failures before they happen, solving the core problem with precision.
Relevant: Smarter than traditional methods — AI-driven, efficient, built for scale.
Essential: Its AI evolves with use, becoming more accurate machine after machine.
The Essential layer was what separated it. The product didn't just solve the problem — it compounded. Each use made it sharper. The business advantage wasn't in what it did at launch. It was in what it became over time.
That reading produced the governing principle for the design challenge: the solution needed its own Essential layer. I started there — at the ceiling — then defined the Functional floor. The Relevant layer emerged as consequence, constrained by both.
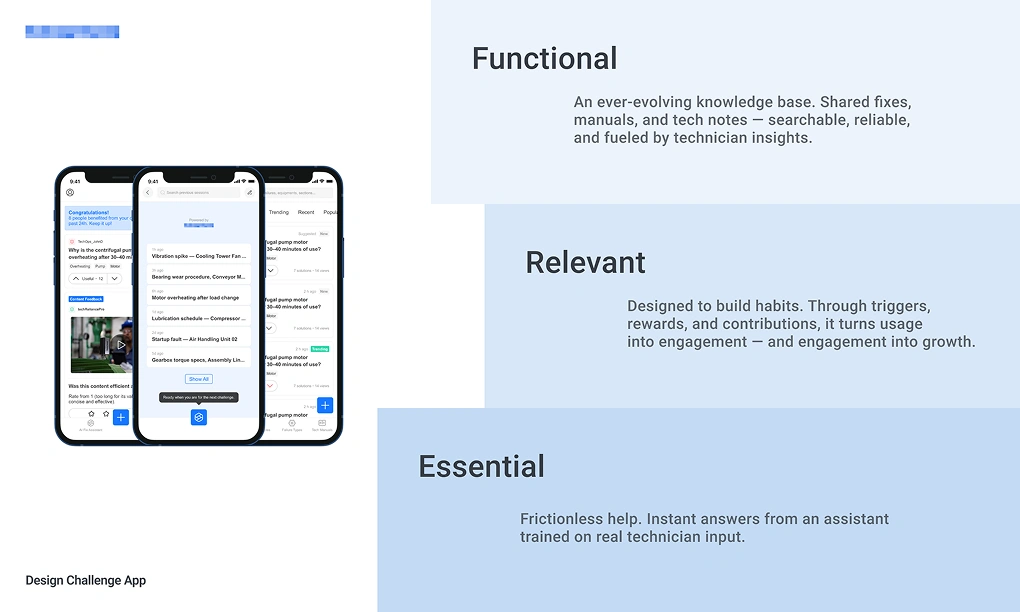
Essential: Frictionless help — instant answers from an AI trained on real technician input.
Functional: An ever-evolving knowledge base — shared fixes, manuals, and tech notes, searchable and fueled by technician insights.
Relevant: Designed to form habits — through triggers, rewards, and contributions, it turns usage into engagement, and engagement into growth.
The conventional response to the brief is Functional at best. A knowledge base with a contribution layer solves retrieval and enables sharing — but it doesn't compound. The knowledge inside it makes the database larger, not the product smarter. No Essential layer. No self-reinforcing mechanism. No reason the product becomes harder to replace the longer it's used.
The principle the Essential goal demanded
The Essential goal — an AI trained on the highest-quality technician knowledge — had one implication that followed with architectural force.
If the AI's value depends on the quality of its training context, every entry the context receives has to earn its place. The first compromise to guard against is social: the moment you allow profiles, follower counts, or contributor visibility, bias enters. Solutions get upvoted because the author is respected, not because the fix works. The AI's context gets contaminated at the source.
So the platform had to be impersonal. Not as a design preference — as a structural necessity derived directly from the Essential goal. No profiles. No influencer dynamics. No way to earn visibility except through the quality of the contribution itself.
And that constraint produced a second-order effect: a platform with no vanity layer can't be extractive even if it wanted to be. Every behavioral incentive has to earn engagement through real outcomes — because there's no follower badge to offer instead. The Essential goal didn't just define the AI architecture. It determined the behavioral system the entire product would run on. What Meadows describes as designing the structure so the right behavior follows — not from enforcement, but from the absence of alternatives.
The diagnosis, the governing principle, and the first coherent actions were all settled before a single screen was drawn. What remained was translating them into architecture.
Architecture
The three tiers didn't just describe the vision — they became the product's scaffold.
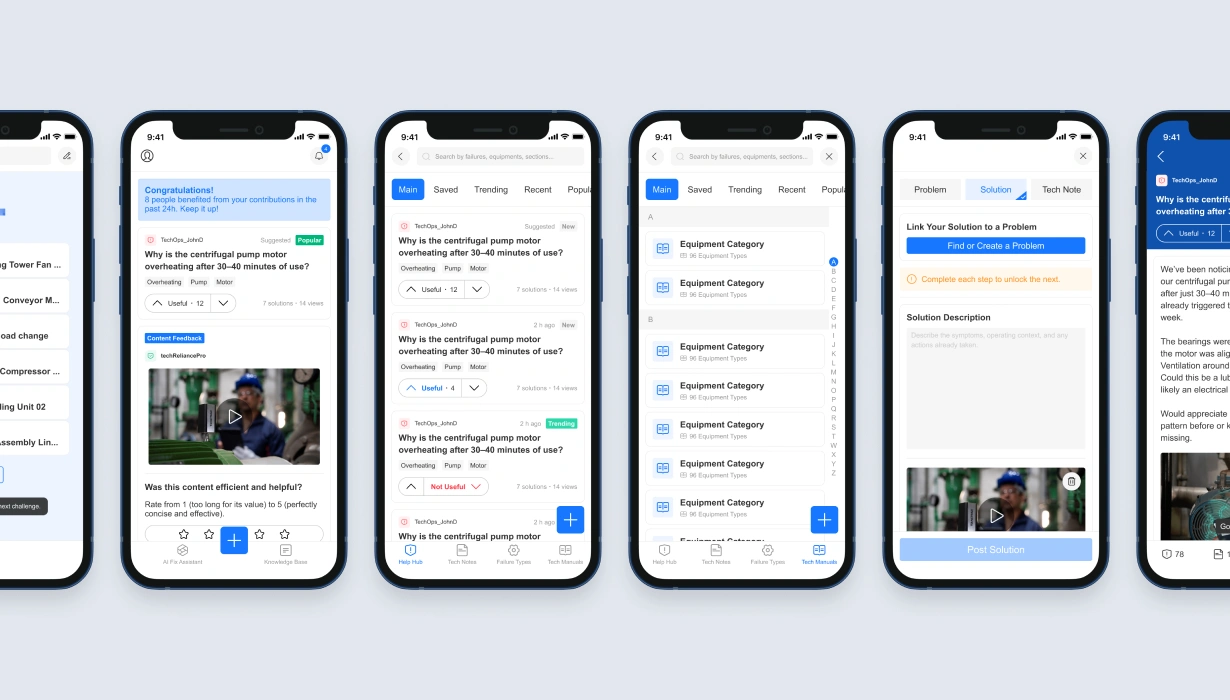
The Functional layer — the knowledge base the brief asked for — became the retrieval and documentation engine: organized by equipment type and failure category, structured around the manuals, failure types, and tech notes that form the raw material the AI depends on. The Relevant layer — habit-forming engagement that turns usage into contribution — became the Home feed: the behavioral surface that connects users to the platform between emergencies. The Essential layer — frictionless help from an AI trained on real technician input — became the AI Fix Assistant: the ceiling everything was built toward.
There's an asymmetry worth naming. Architecturally, the Essential layer is the ceiling — the reason the product exists. Operationally, the Relevant layer carries more weight: without the habit it produces, the AI has no input to learn from. The AI is what the product is for; the Home feed is how it gets there. That's why Home is the default view — not the AI Fix Assistant.
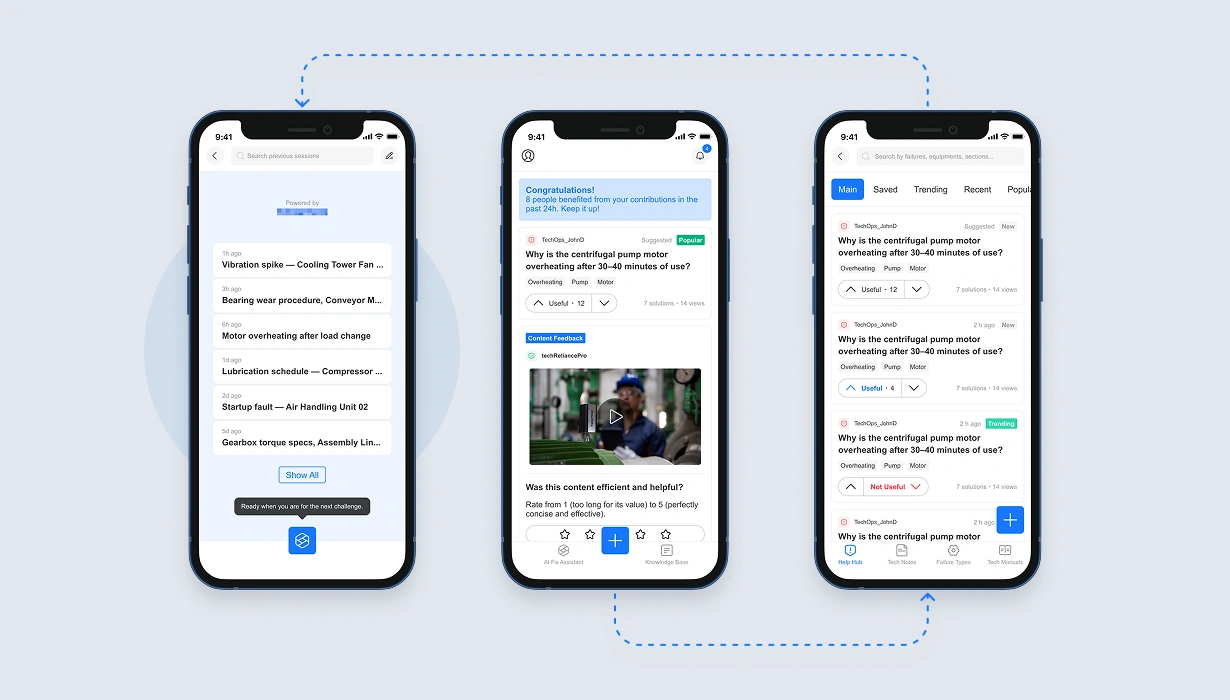
The Knowledge Base feeds the AI Fix Assistant — it's the human-readable face of the LLM's context, where every manual, tech note, and documented solution becomes part of what the AI knows. The Home feed drives contribution back into the Knowledge Base — not through prompts or nudges, but through behavioral architecture that makes participation the natural path. The AI is the destination. The Knowledge Base is its memory. The feed is how that memory keeps growing.
Protecting the context
The impersonal content principle established in Diagnosis demanded specific design decisions — each one protecting the quality of the AI's training context. Three carried most of the weight: what the platform refused to accept, what signals it chose to capture, and how it displayed what it had.
No comments. Not just because supersession produces better contributions — but because comments would litter the AI's training context with noise. Congratulatory messages, tangential observations, delivery critiques — none of it helps the model answer the next technician's question. The same efficiency principle that drives the product's reason to exist — keeping machines running — governs what's allowed into its knowledge base. If it doesn't improve the context, it doesn't belong. Supersession, as the correction mechanism, produces exactly what the AI needs: a better answer, not a conversation about the existing one. And because the platform has no vanity layer, superseding someone's solution carries no social cost — there are no profiles to offend, no followers to alienate. With time, the community's own patterns start guiding contribution quality: if concise, media-rich solutions consistently outperform verbose text-only entries, contributors learn what earns traction by observing what works — not by reading guidelines.
Upvotes — and downvotes. In platforms built around human connection, negative signals are often suppressed — they feel unkind, they create friction. Here, they were necessary. An uncontested upvote system produces popularity, not accuracy. Every downvote is a data point the AI needs — a signal that this solution didn't hold, that the context should weigh it differently. The same Essential goal that removed comments for being noise demanded downvotes for being signal.
Three solutions at a time. Not a simple top-N list, but three structurally distinct slots: the most validated solution, the trending one challenging it, and a recent entry offering a new take. Each slot represents a different axis of the solution space — trust, momentum, novelty — creating a continuous multivariate test embedded in the interface. The popular solution isn't permanent: older votes lose weight over time, so the community's judgment stays current and newer contributions always have a path to visibility. Progressive disclosure for the reader; a living evaluation system for the platform.
The behavioral engine
Protecting the context is only half the job. The other half is building the surface that makes contribution happen in the first place — and makes it happen often enough to compound.
The Home feed is the default view, and that's deliberate. It's where the platform earns habitual usage, not just crisis-driven visits.
Industrial maintenance doesn't produce a constant stream of emergencies — and the company's own predictive systems are designed to reduce them further. Technicians have idle time — paid capacity the buying company is already funding. The Home feed is designed to reinvest it: the hours between failures become hours of community participation, skill development, and knowledge contribution. For the operations leader evaluating the platform, that's training, retention, and workforce value compounding from time already on the clock — not new spend.
The feed's components are where the behavioral architecture becomes most tangible — each one designed to trigger a specific behavior, reward it, and convert it into platform investment.
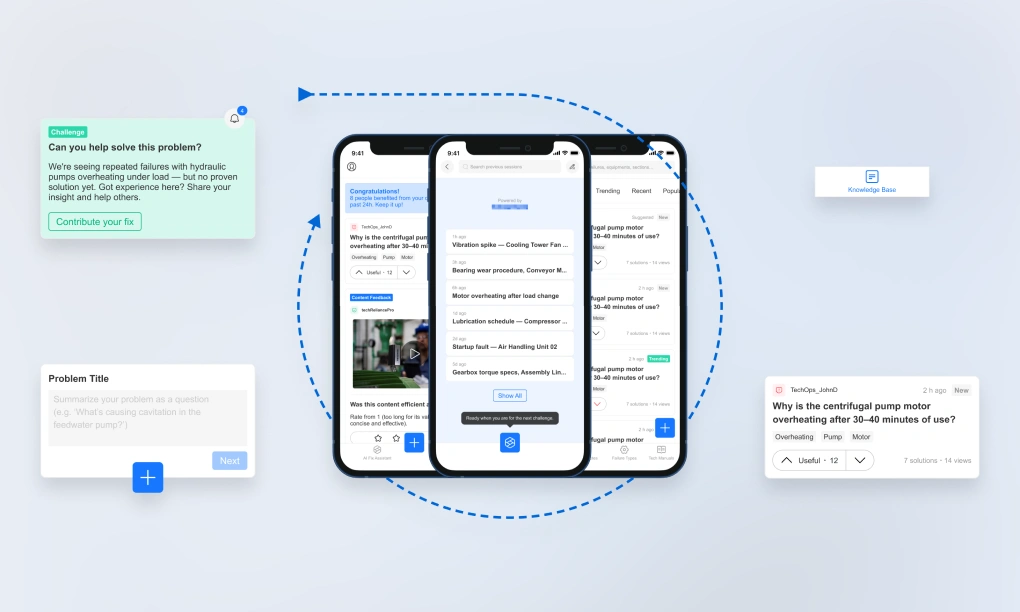
Toast components surface the impact of recent contributions: "8 people benefited from your contributions in the past 24h." Not vanity metrics — genuine outcome signals, each one reinforcing an internal trigger: the emotional association between professional value and platform engagement. Internal triggers — the moments when a user's own feelings or routines prompt them to open the product without any external prompt — are the most durable form of habitual engagement. And here, the trigger is generative: what brings the technician back is seeing that their expertise made a difference, not a notification engineered to create anxiety. The platform earns the habit by deserving it.
Rating cards ask the user to assess a video solution they previously watched — scoring it for both effectiveness and efficiency. Double duty: they validate the content for the database while teaching contributors what "good" looks like. Users who rate concise, effective solutions learn — through the act of assessment itself — that their own contributions will be held to the same standard.
Challenge cards are how ML pushes under-solved Problems to the technicians most likely to answer them, based on contribution history: "We're seeing repeated failures with hydraulic pumps overheating under load — but no proven solution yet. Got experience here?" The Problem is the same one anyone else can browse in the Knowledge Base; targeting only determines who sees the invitation.
Retention, in this architecture, is structural — not promotional.
A contributing technician doesn't just use the knowledge base — they shape the one their workplace depends on. Every upvote weighs a solution. Every challenge answered adds a new one. Every solution composed enters the ranking. Each is simultaneously engagement and contribution; each contribution reshapes what the next technician finds. The more a technician contributes, the more the product carries their expertise — and the more switching platforms would mean leaving behind what they built.
No loyalty program earns that. No retention campaign engineers it. The architecture does.
The connective tissue
If the behavioral surface is how the knowledge keeps growing, the tagging system is how it stays connected — making the architecture's intelligence visible while keeping contribution frictionless.
Core and secondary tags are inherited automatically from parent entities: Failure Types, Equipment, Manuals. When a technician submits a solution to a problem linked to a specific equipment type and failure category, the entry arrives pre-tagged — connected to the broader knowledge graph without requiring the contributor to do the connecting. Only tags specific to the individual contribution need to be added manually. The AI's context grows with every entry, and the structure that makes it searchable for humans is the same structure that makes it trainable for the model.
Architecture was settled before screens were drawn. What remained was seeing what the structure would produce.
Outcome
Each section of the product was designed to serve the others — but the architecture's most significant outcome operates at a level above the product itself.
The company's existing products monitor machines in real time and generate data about failure patterns — identifying problems, diagnosing their causes, and in many cases pointing to a documented fix. For the ones they couldn't — novel failures, rare patterns, problems the database hadn't seen — the loop stayed open. The knowledge platform closes it. When the ecosystem detects a recurring failure without a proven solution, ML elevates it into a Problem in the Knowledge Base — and the community of technicians contributes the answer. The AI learns from their input. The next time the same failure appears, the platform surfaces the most likely fix — and a technician can apply it faster than starting from scratch. With every cycle, the time between diagnosis and resolution gets shorter. The platform doesn't just sit alongside the company's existing products. It completes them.
When the solution was presented, the COO described it as the strongest submission the design challenge had ever seen.
Not everything in a design challenge is ready for production. The architecture here is a hypothesis — derived from reasoning and company analysis, not from validated behavioral data. The impersonal content principle is logically sound; whether technicians would experience it as liberating or cold is a question only real usage can answer. The Triadic Solution Display is architecturally motivated; whether three solutions is the right number requires testing. Confidence in a structure is not the same as evidence for it. In a real engagement, this would be the beginning of discovery — not the conclusion.
The lesson
The brief asked for a tool to help technicians find answers. Treating it as a discovery process — studying the company's products, mapping their vision, deriving a governing principle before drawing a screen — produced something different: a platform whose AI improves every time a technician contributes, because the behavioral architecture was designed to make contribution the path of least resistance.
The architecture didn't need to enforce it. It just made anything else structurally harder.
